As I mentioned the other day, I fell in love using Tailscale for making my local private network accessible remotely. I’m also using this in my company, but with one colleague, had an issue, I didn’t find any documented solution online. So here is mine.
I have a Tailscale network with multiple self-hosted services running in Docker and made available with Tailscale. If you have an account and your account is invited to the network, you can access them. This worked for 2 of 3 colleagues. The third had the Tailscale client running on their Windows, it showed up as active in the Tailscale admin console and the list of machines. It looks like it runs perfectly, but when you try access the the service within the network, it fails in Firefox with the error PR_END_OF_FILE_ERROR or SSL_ERROR_INTERNAL_ERROR_ALERT. In other browsers the error would just show as a connection error.
If you put the service in a public Tailscale tunnel, access is possible. if you go on their machine, open Powershell and call tailscale status it would show all status just fine. Calling tailscale ping <service-name> shows success ping to the service.
I tested Windows defender and firewall settings, but could not find anything that could explain the issues.
Calling tailscale dns status provides on the machine provides an overview of the dns options Tailscale is using. Here it showed this:
=== 'Use Tailscale DNS' status ===
Tailscale DNS: disabled.
Tailscale is configured to handle DNS queries on this device.
Run 'tailscale set --accept-dns=false' to revert to your system default DNS resolver.
So I switched this on:
tailscale set --accept-dns=true
Et voila, calling the service work again!
So now I’m in this half-satisfactory space of having a solution, but not knowing the root cause. My guess is that this colleague hasn’t updated Tailscale since them installed it initially in October and when they installed the latest version, it did not install the latest default configurations properly.
My expectation would be that turn Tailscale DNS off again, would lead to the same issue, but it didn’t.
tailscale set --accept-dns=false
So something is weird, is resetted when activated DNS and stays good when deactivating it again. Well it works, for now and I hope it’s a permanent solution.
Es gibt Filme, die holen einen im richtigen Moment ab. Inside Out 1 und 2 waren so Filme für mich.
Inside Out kam während eines “messy breakups”, einer Zeit, die von vielen mentalen Tiefs geprägt war und in der ich mich erstmals mit dem Thema Depression beschäftigte.
In Inside Out 2 erreicht Riley die Pubertät und mit Anxiety übernimmt ein energetisches Chaos das Steuer. Meine Anxieties waren mir lange nicht bewusst. Erst in den letzten Jahren lernte ich diese zu erkennen und einzuhegen.
Nachdem ich aus Inside Out 2 kam, ging ich durch das nächtliche Wien und machte mir Gedanken über die Filme. In Beiden besteht ein eine gewisse Dissonanz wie “groß” das Ereignis in der realen Welt und wie heftig und episch die Reaktionen in Rileys Kopf sind. Wenn ein Umzug, zur gezeigten Verstimmung führt und ein schlechtes Wochenende zur Kapitulation vor Anxiety, ist die Wahrscheinlichkeit hoch, dass diese Episoden keine Einzelfälle sind und Riley öfter mit Mental-Health-Themen zu tun haben wird. Mangelnde Regulation von Emotionen ist ein Symptom von ADHS. Wie cool wäre es, wenn Riley im nächsten Film ihre Diagnose als neurodivers erhält!? Oder im nächsten Film eine neurodiverse Person neben Riley gestellt wird!?
So gingen mir einige Varianten durch den Kopf, wie ich mir von Inside Out 3 vorstellen könnte.
Eine Frau geht durch einen langen Flur. Man sieht ihr Gesicht nicht, aber der blonde Pony lässt keinen Zweifel, dass es sich um Riley handelt. Sie trägt eine Brille – Nahaufnahme ihrer Augen – sie zeigen leichte Krähenfüße und deuten auf ein Alter Anfang 30. Sie stoppt vor einer Tür. Sie fasst den Türgriff, aber hält inne. Sie atmet ein. Das Türschild zeigt “Psychotherapie Dr Erica”. Sie atmet aus und betritt das Zimmer. Ihre erste Therapie-Stunde. Ein Neustart: 20 Jahre depressive Episoden, Selbstzweifel, Rejection-Sensitivity – verkrustete Glaubenssätze warten auf Aufarbeitung und Lockerung.
Zoom in ihren Kopf – an der Konsole streiten sich Ennui, Embarrassment und Fear. Sadness, knackt ihrer Finger: “Lasst uns beginnen!”
Back in 2018 I had a problem. I was writing song lyrics in Evernote, but displaying them for playing was annoying. I started work on Everchords a tiny platform allowing you to connect your Evernote account and display SongPro lyrics beautifully. Over time I added more convenience features for songwriting that helped me a lot to streamline my song writing process. This was a big help when producing Bettlektüre.
All this ended a year ago, when I stopped using Evernote. So it wasn’t part of my workflow anymore. I kept doing security updates, but these took more effort lately. I thought for a long time how to continue it, but ultimately, I don’t know. I’m using Obsidian.md now, which does not have similar APIs. While all data is fully accessible being “just markdown files”, there is no default pipeline to process and there are so many ways to build this pipeline, that it makes little sense to build and maintain a full platform around this. So I decided to take #Everchords offline.
The itch it scratched is still there, as I write my notes in #Obsidian, I may want to have a better songwriting experience again. We will see in time how I will change my process, adopt a different tool set or build something again to cover this.
In part one I spoke about the start of my journey, which was driven by playing with my smart home playground on topics of energy saving. My home servers have been in place since 2018 – yet, one thing I could never fully solve was how to make it available outside of my home network. For people into DevOps there will be little new here, but I’m no DevOps guy, so I had new things to discover I’d like to share.
So my challenge was to make my home server available via the internet, without making it public.
I was toying with a DynDNS setup at one point, but I never felt comfortable with exposing the full device to the internet. I know my way around Linux, but server security can become a bigger beast. I also didn’t want to invest in a virtual private server setup for this.
This is where Tailscale was a small revelation to me. Tailscale is a service provider for virtual private networks. Basically, you install client apps on your devices building a virtual network and making machines available even when they are physically apart. For example, I’m traveling and by flipping a switch on my phone, I see my PCs, my home server, my second phone, and I can access them as if they were in the same room with me. Each device gets a fixed IP and URL in the network and becomes way easier to access than remembering IPs and ports. I could add the Tailscale client to my Home Assistant OS running Raspberry and can access it from everywhere, as long as the Tailscale client is running on my device. This was straight forward.
What took me some time to learn was integrating not only physical devices, but also virtual containers. What is a virtual container? Basically, systems like Docker or Podman simulate a very slim computer environment specifically set-up and optimized to run one particular software stack. For example I can set up a web blog with the client frontend, backend server and database – each running isolated in their own Docker containers – easy to scale. Here you can find more about the basics of Docker and how to get into it step by step. I had my first contact with Docker in 2018, but never got around to fully embrace it until now, but grew to love docker-compose quickly. This allows you to create and find recipes to quickly set up full tool stacks easily and self-host your own software infrastructure.
What is Immich? I wanted to get rid of Google Fotos. I used the service for a long time with much appreciation, but eventually wanted to have more control over my data on the eve of Google using its foto database for AI training, I wanted to withdraw my pictures and also have better organized backups. The easiest alternative I can recommend is ente.io which also comes with more tools around data security and multifactor-authentication (MFA). This option is simple to switch to, but still your data is not in your own infrastructure.
Immich has very similar functionality to Google Fotos and quick to set-up with Docker. You can import your existing fotos either as an external library (very straight forward and simple, but at the cost of small limitations around cleanup options) or by importing all pictures via the API by uploading through the the web interface, the Mobile API, command-line scripts or additional tools like Immich-Go. My photo library has been growing in my filesystem since 2002 and while it is generally well maintained, it slowly became messy, incomplete, metadata was lacking and suffered from duplications. These were all topics Immich and its extended toolchain helped to address. That is, if the photographs are imported in the “right way”. For me it involved three attempts on my side as image duplications on upload, mistaken metadata and lack of testing my own cleanup scripts (xD) caused several broken attempts with Immich. The software is stable and good, but my ambition in cleaning my library was just too big. May the backups be thanked – these setbacks did not cause any data loss – just wasted time. On the third attempt it worked well.up. I picked Immich as one example, but there are plenty more tools available to self-host and especially play nice with Tailscale.
Immich runs on my NUC 11 in a Docker-Compose setup and thus was now available in my home network, but again I wanted it accessible when I’m away from home. This is where we come back to Tailscale. Above we only added physical machines to Tailscale, but it is also possible to add virtual containers to the private network. Each container becomes available as its own machine which now becomes available to everyone in your network to access.
Everyone? Oh, yes, I forgot. You can share your private applications in two ways. You can invite up to 3 people (in the personal free account) to your network and they can have access to all machines if you allow it. Alternative you can share access to single machines to people who already run their own Tailscale network. This way you and your peers are building their own private little part of the internet hosted on your own infrastructure. You can also define machines as exit nodes and thus create your own little distributed VPN. Invite trusted friends over the world and you can run traffic through each other’s exit nodes and now I can watch German Netflix and my friends in Germany can watch Austrian ORF.
Tailscale is providing a good bundle to start your DevOps networking journey. All it offers can be done in other ways with less reliance on a central service orchestrating this network as Tailscale does. However doing this this manually is difficult, complex with a high risk of mistakes that compromises data security – these are factors I’d like to entrust to experts. Tailscale also has a learning curve, but one that is much faster to handle to get into the basics.
Through Tailscale and Docker I have a new toolchain that runs at home, that I have a lot of control over including full ability and responsibility to backup. I picked Immich as one example, but there are plenty more tools available to self-host and especially play nice with Tailscale.
In my next article, I will look into another example, that grew out of Docker and Tailscale at work and that describes a self-hosted alternative approach to a Data Intelligence pipeline in the context of a non-technical company.
I have not been writing code for a year, but my current job is still about providing and choosing technical solutions based on requirements and context. While the company I work for has a strong direction towards GenAI and Microsoft solutions (who doesn’t…), in my private projects I look into the other direction of Small Web, Decentralisation, Self-Hosting and the Rot economy of Tech these days. This also proofed a good opportunity to dive deeper into Home Automation and Docker. It’s an ongoing process, but here I’d like to talk about a few pet projects I did in the last year.
It started back in early summer 2023, I got myself some Shelly smart plugs , installed [Home Assistant]() and began to measure my energy consumption. This ran on my mini-pc – a small Intel NUC 11 Performance – I had been using for a year for backups, but little else. The NUC was an upgrade from a RaspberryPi 3 running dietpi I used for the same purpose. For convenience sake I kept using dietpi also on the NUC 11.
By measuring energy consumption, replacing inefficient devices (ffs get rid of old light bulbs!) I was able to reduce my already low energy consumption by another 20%. Having this visually not only helped reducing total consumption, but also shifting consumption to times windows which are either cheaper by having a lower hourly price or by optimizing for lowest CO2 usage by consuming when most renewable energy is in the grid. Often this coincides with low prices, but not always.
Since working on energy projects professionally and switching to a dynamic energy tariff in February I have been looking more into energy topics. In between I tried to build a predictor that could guesstimate the energy prices for upcoming days based on weather and other factors, but eventually I realized, that this is fruitless as the prices is a negotiated market price based on consumption expectation across all of Europe. To say it simple: the price is not only caused by weather, it’s set to provoke and steer market reaction. I have not the data to predict that.
What is more helpful is experience. On average daily energy is cheapest during the week between 3-4am and 11-2pm. Avoid the 6-8pm evening peak. On the weekend, consume between 11-4pm – sometimes you are lucky and zero to negatives prices. By timing dishwasher and washing machine accordingly, 50% of my consumption falls into the cheapest times. On a regular day, I have 2kWh consumption split with laundry, kettle and dishwasher each at about 1kWh per run being the most hungry devices. Another 1kWh falls to my Tech and I can see in my consumption, when I run the gaming PC with VR. Despite my below-average consumption, I have been dancing around getting a balcony solar-installation for almost a year. At 300€ these have become sooo cheap… story for another day.
I managed all smart home devices in Home Assistant. in the beginning, this ran on the NUC managed by dietpi. Eventually in Spring this year I reactivated the raspberry after all, to run Home Assistant OS on it instead. This offers some more customization and supervising options, necessary to install more custom plugins and integrations. Add the Home Assistant App to this and you have a neat remote for your home. I stopped tinkering here with Home Assistant at this point, although topics like MQTT data broadcasting are still on the list of things I’d like to checkout one day.
Home Assistant at this point was in my local network and only accessible at home. How to make it available remotely and what other infrastructure I started hosting at home, I’ll cover in part two.
Ein Kessel, der ständig überhitzt, unter Druck steht und das erste Mal abkühlt. Die Welt läuft 5% langsamer und erstmals in der selben Geschwindigkeit wie ich. Eine neue Ruhe im Körper – die Anspannung ist weg.
Elvanse lag 8 Monate in meinem Schrank. Zwei Pillen sind einer lieben Freundin vom Laster gefallen für “wenn ich mal schauen will, was an ADHS dran ist”. Seit dem schob ich es immer vor mir her, dieses Experiment zu beginnen.
Dann kam der März. Am Ende meines ersten Experiment-Tages, schilderte ich ihr meine Eindrücke und sie schrieb trocken “Willkommen bei den Neurodiversen”. Elvanse ist ein Amphetamin, eine Stimulanz – mit einem neurotypischen Gehirn, wäre ich an dem Tag aufgedreht durch die Gegend gesprungen. [1] Stattdessen war ich ruhig, entspannt und konnte das erste Mal seit langem drei Stunden konzentriert arbeiten. Alles war zugänglicher, eine komplett neue Körpererfahrung. Damit war es klar. Ich habe ADHS.
Seitdem habe ich meine offizielle Diagnose und ich rede regelmäßig drüber. ADHS endlich bestätigt zu haben ist für mich auch ein Coming-Out. I come in pride. Neu ist mir das Thema nicht, Freunde hatten schon lange die Vermutung und ich wusste ebenso lange, wie ich mich in dem Thema wiederfinde. Gleichzeitig fühlte ich mich wohl Schrödingers ADHSler zu sein und nicht klar als neurodivers oder neurotypisch eingeordnet zu sein. Nun ist diese Einordnung eindeutig.
Die Reaktionen in meinem Umfeld waren fast durchgehend in einem von zwei Lagern: Das “No, shit sherlock”-Camp, dass als Erstes fragte, ob die Diagnose für mich überraschend sei. Dem gegenüber steht das Lager “Rehblick” – Menschen, die mich mit großen Augen überrascht und verständnislos anschauen. Deren erste Frage einfach ist, wie es mir damit geht. Danke sehr gut.
Seit dem Sommer hab ich die offizielle Diagnose und bekomme meine eigenen Medis. Ich bin aufgewachsen als jemand, dem immer eingetrichtert wurde mit Medikamenten solange zu warten, wie es geht. Dies lege ich langsam ab. Für Menschen mit Sehschwäche ist eine Brille ein total normale Hilfe. Für Menschen mit einem anders verdrahtetem Gehirn, sind halt Medikamente die Sehhilfe. Ich hab lang genug gezeigt und bewiesen, wie weit ich ohne komme und zu welchem Preis.
Ein Thema, nach dem ich auch gefragt werde ist, ob ich mit Medikamenten nicht die “Fähigkeiten” verliere, die mich aus machen, bzw die ADHS mir gibt. Ich bin top organisiert, super Problemlöser und klasse in Analyse, Pattern-Matching und letztlich vielseitig und kreativ. Ja, den Gedanke, das zu verlieren hatte ich auch, jedoch hörte aber von allen Seiten, dass dies nicht passieren wird. War auch nicht so. All dies blieb Teil von mir, ich gewinne aber Fokus um es besser umsetzen und stärken zu können.
Trotzdem ist es natürlich nicht nur rosig. Ich freue mich über die Diagnose und die Möglichkeiten nun Erleichterung zu finden. Ich sehe auch, wo ADHS mir in den letzten 30 Jahren viele Steine in den gelegt hat. Manche konnte ich selbst von alleine navigieren – andere nicht. Ich bin stolz, was ich in der Zeit alles hinbekommen habe und es gibt trotzdem auch Momente der Trauer, was mir verwehrt blieb und, dass diese Diagnose Teil meines restlichen Lebens sein wird. Einige Dinge werden niemals leicht werden und ich weiß, wie ich manche Themen derzeit auch noch nach hinten schiebe, wo ich selbst eine neue Position entdecken muss, bzw meine Alte reflektieren werde.
Ich dachte vor 6 Monaten es würde jetzt ein ewig langer Side-Quest beginnen, bis ich Diagnose und die Verschreibung habe. Aber ich bin sehr glücklich, dass durch gute Vernetzung und die Hilfe toller Menschen, alles sehr schnell ging. (Therapeuth*Innen, hört auf die Selbstdiagnose eurer Neurodiversen.) Darüber bin ich sehr dankbar und nun nach einem halben Jahr kann ich mir nicht mehr vorstellen, wieviel Lebensqualität ich ohne die Medikamente auf der Strecke ließ.
[1] Eine andere Freundin schrieb später, sie hätte ADHS herausgefunden als sie gerade feiern war, sich Amphetamine einwarf und wunderte, warum sie plötzlich so hochkonzentriert und fokussiert ist.
Over the past week I have been playing with a self-hosted instance of n8n – a Zapier-like automation platform. I quickly ran into an issue, that took a while to debug and I’d like to share my solution here.
I live in Timezone Europe/Berlin, so I added the timezone ENV-variable. The container starts fine and I can create workflows.
Now the weird thing was that date/time processing was broken.
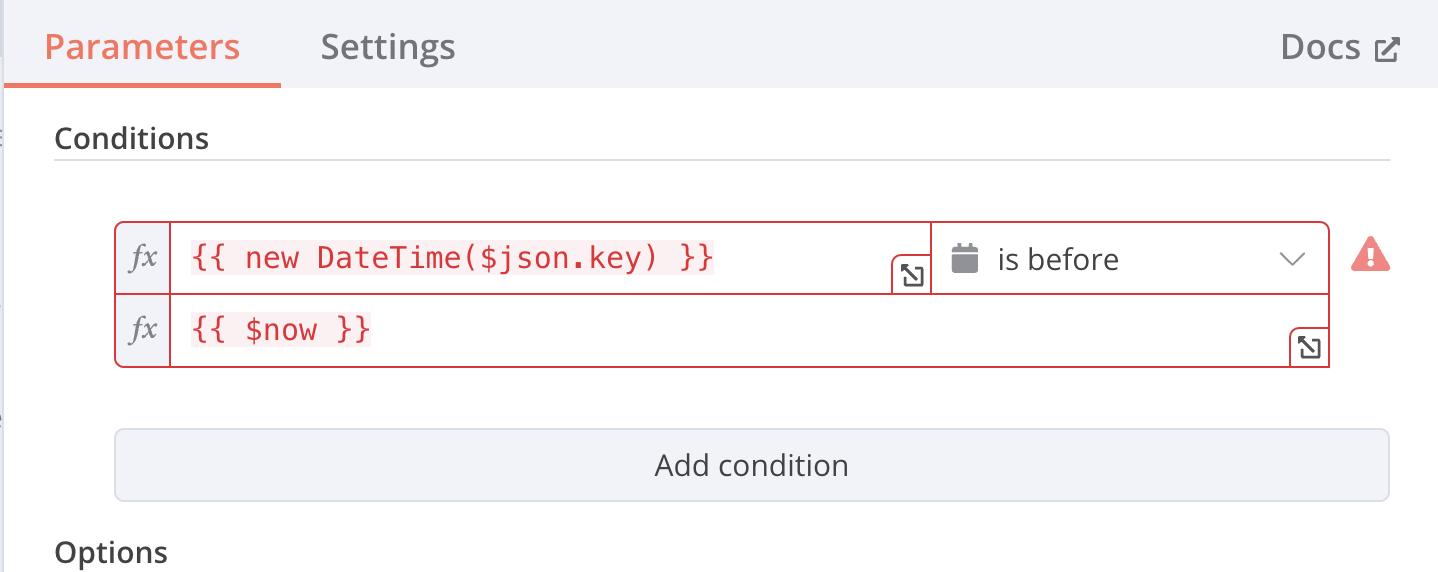
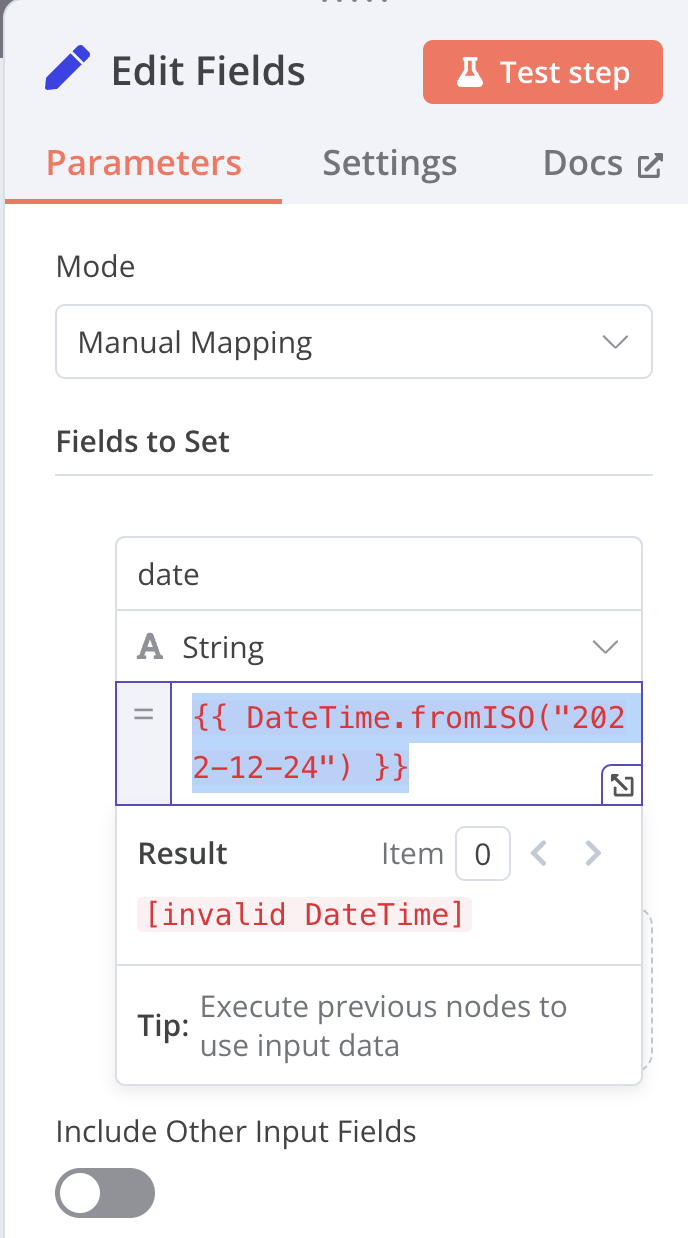
Whenever I would create date/time converting nodes or expressions like {{ $now }} or {{ new Datetime("2024-05-12") }} or {{ DateTime.fromISO("2022-12-24") }} it would always bring up an error message Result: [invalid DateTime]
Which turns out is just wrong… writing it this way has the quotation marks as part of the string thus the timezone n8n was parsing wasn’t ‘Europe/Berlin’. but ‘”Europe/Berlin”‘. Removing this faulty line, the date/time processing with Luxon worked like a charme!
…
- GENERIC_TIMEZONE=Europe/Berlin
–
So getting Invalid DateTime means, luxon fails to parse the timezone and can’t return a valid result. You can try this also with unknown time zones like “Europe/Berlin123” – same error. So fix your time zone config and the error will vanish!
Seit über 15 Jahren gehören Podcasts zu meinem täglichen Medienkonsum. Da mich auch immer mal wieder die Frage erreicht, welche ich empfehlen kann, gibt es hier meine Liste geordnet nach verschiedenen Themenbereichen. Dabei sind nicht nur aktuelle Podcasts, sondern auch einige Abgeschlossene. Ich finde nämlich Podcasts schließen viel zu selten ab und ihr Ende wird oft viel zu lang hinausgezögert.
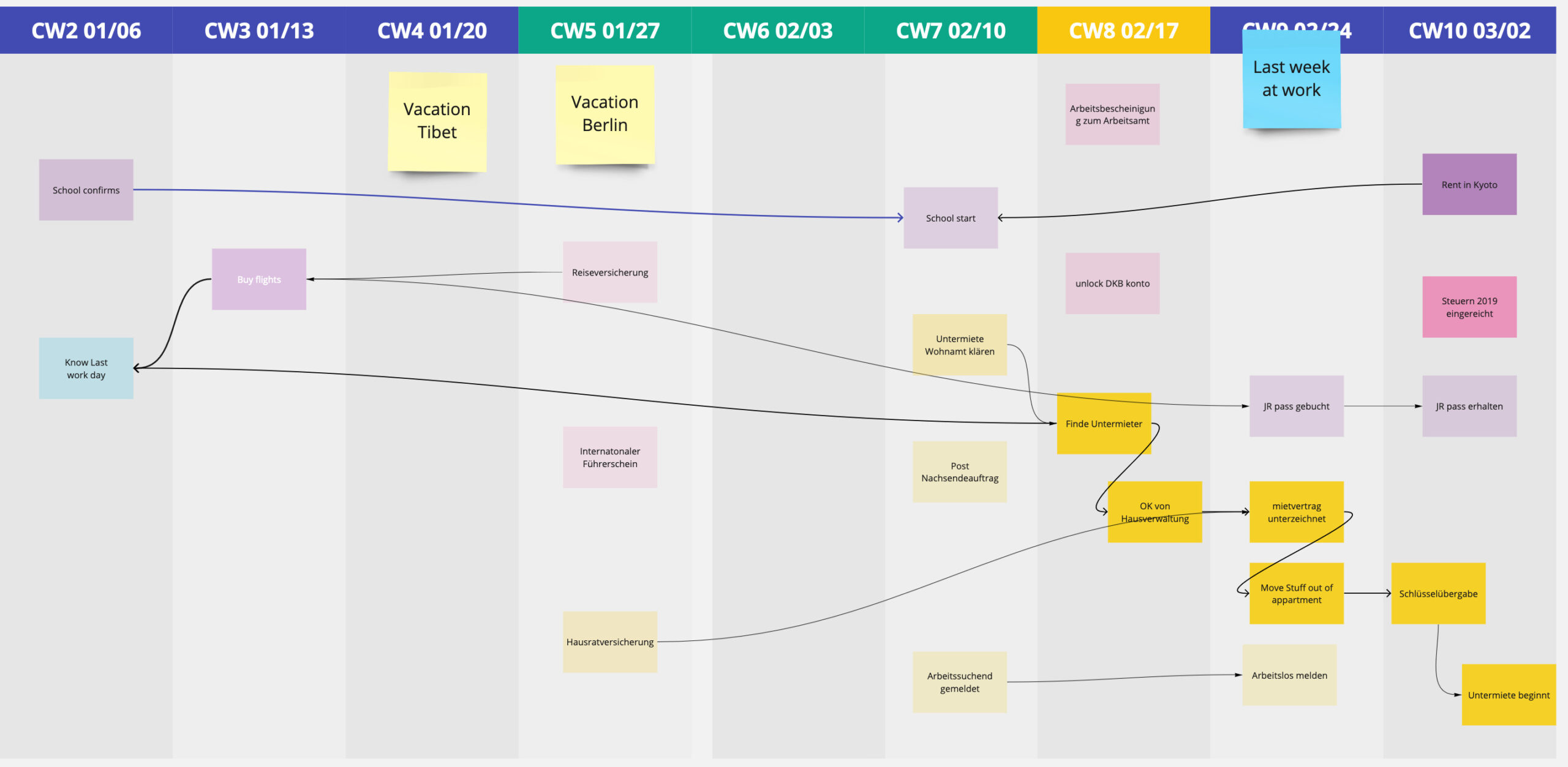
In the last 5 years I as Product Manager, I often found myself disliking the common ways on how to express project status and deadlines. They’d either hide important complexity or are a mess to keep up to date. Over time have grown a visualizations technique and meeting format I call the Weekly Dependency Chart. This helped me get structure and overview in projects I inherited, that were complex, late or required reliable schedules. I applied this in several private and professional contexts successfully. It was originally inspired by the Puzzle Dependency Charts used by Ron Gilbert in his adventure games.
The idea is to have a quick high level overview of timelines, to-dos, blockers all lined up in a weekly calendar view. Each item connected to the items it’s dependent upon. Over time this graph evolved into a meeting structure, you can use to keep the overview up to date while synchronizing the status with the people involved.
Platt drückte sich ihr Hintern auf die Sitzfläche des weißen Holzschemel. Sie merkte die Unebenheiten seiner Oberfläche. Die platzende weiße Farbe täuschte nicht über den abgenutzten Zustand des Holzes hinweg. Der kleine Spalt würde nach dem Aufstehen eine kleine Markierung auf ihrer Wade hinterlassen. Kein Schmerz, aber sie spürte es. Wie das Jucken, dass ein jeder Mensch hat, wer bei geschlossenen Augen in sich reinhört. Sie lächelte.
Sie rutschte etwas, betastete seine Beine. Ihr Blick wanderte ihrer Hand hinterher, wie sie an einem entlang stricht. Dieser sollte es sein. Er war perfekt. Sie nahm die Säge und setzte an.
Drinnen war nichts zu hören. Niemand hegte verdacht.
Im Dezember war ich eine Woche in der nähe von Neapel unterwegs. Mehrmals kam es, dass ich aus dem Zug ausstieg, direkt in den nächsten lokalen Bus wollte und nicht gefunden habe, wo ich Bustickets kaufe. Es ist aktuell ein ziemliches Elend. ÖPNV-Unternehmen sind entweder gar nicht digital oder jedes hat seine eigene Ticket-App. Ich habe selbst 2021-2022 an der ÖPNV-App in Wien mitgewirkt und kenne die politischen Spiele, die dahinter stehen. Die Unternehmen wollen keine offenen Schnittstellen, sondern selber die Hand über dem Ticketverkauf haben, bauen gleichzeitig aber nicht die nötige Infrastruktur und Know-How auf um dies bequem anzubieten. Das Ergebnis ist, dass jede Stadt, jeder Landkreis, jedes Bundesland unterschiedliche und nicht-miteinander kompatible Apps verwenden. Als Reisender in dieses Trara reingeworfen zu werden ist Scheiße.
Nun war ich in Italien dieser Reisende und die Idee für Kebus kam auf.
Kebus ist eine kleine Web-App, die für deine aktuelle Position die verfügbaren Apps für den öffentlichen Personennahverkehr ausgibt. Derzeit sind etwa 50 Apps für über 60 Regionen enthalten. Das reicht von einzelnen Städten bis ganze Länder – hauptsächlich Europa. Derzeit ist es noch sehr kompakt, es spuckt nur die Apps für die aktuelle Position aus. Es gibt noch keine Suche und Ticketverkauf wird nie enthalten sein. Für mich war es mal wieder ein Pet-Projekt um einige Technologien zu testen. Der Aufwand liegt aber in der Pflege und das ist ohne lokales Wissen durchaus kompliziert. Wie es weitergeht hängt jetzt etwas davon ab, ob ich etwas Traction sehe.
Wenn in deiner Gegend noch keine App eingetragen ist, dann gerne Mail an mich – am Besten welche App für welche Region hinzugefügt werden soll.
Neues Jahr, neue Runde an Spiele-Empfehlungen. Mit dem Rückgang der Pandemie und einem neuen Job sind diese etwas weniger als in den Vorjahren. Wo möglich verlinke ich wieder auf die offiziellen Seiten, wo alle möglichen Store-Links zu finden sind.
Als ich 2014 mit Songwriting began hatte ich ein Problem. Ich lernte in dem ich Songs nachspielte und dafür die Texte und Akkorde nachspielte. An die zu kommen ist meistens nicht schwer, aber die sich auf eine kompakte und nicht-nervende Art anzeigen zu lassen war fast immer unmöglich. Seiten wie Ultimate Guitar, oder ähnliche haben zwar große Kataloge, aber die visuelle Aufarbeitung und UX ist oft mangelhaft. Liedtexte werden meist vertikal dargestellt, Akkorde als Zwischenzeilen – fast immer sprengen sie die Bildschirmhöhe, wodurch Scrollen nötig wird. Das versuchen manche durch Auto-Scroll zu kompensieren, aber geil ist es nicht. Will man die Texte mal ausdrucken ist das Resultat auch eher schwach.
In meinem Songwriting-Prozess, iteriere ich viel über meine Texte. Ich schreibe, ich spiele, ich ändere und das auch oft unterwegs. Tools wie Ukegeeks Song-O-Matic kann man auch selbst hosten und bieten gute Funktionen, aber leider fiel es mir schwer meine Songs zwischen der mobilen Notizen-App und dem Song Editor synchron zu halten. Es brauchte etwas, das beides verbindet.
2015 entstand die erste Version von Everchords, einem schlanken Frontend, dass Evernote als Song-Datenbank nutzt. Notizbücher in Evernotes, die meine Songs als Notizen enthalten werden in Everchords importiert und Everchords bietet dafür eine Oberfläche, diese Songs genau so zu formatieren wie ich es brauche. Ãœber die Zeit wuchs dies ein bisschen, aber nicht massiv. Das Tool sollte immer kompakt und den Focus auf die Song-Inhalte haben. Grifftabellen und Akkord-Diagramme kamen dennoch mit der Zeit dazu.
Die Anbindung von Evernote ist gleichzeitig die größte Stärke und die größte Hürde. Evernote ist zufällig mein Notizentool und bietet im Gegensatz zu vielen anderen eine gute API zum Synchronisieren von Inhalten. Allerdings ist Everchords ohne Evernote nicht benutzbar wodurch eine Nischanwendung noch weiter in seiner potenziellen Zielgruppe eingeschränkt wird. Dies ist letztlich auch der Hauptgrund warum ich es nie größer gezogen oder ein vollständiges Produkt draus gemacht habe. Dies ist ein Tool, für mich, für mein Songwriting und ein Pet-Projekt um bei Programmieren nicht ganz einzurosten.
Warum nun schreib ich davon: Everchords ist nun auf www.everchords.app dennoch online gegangen und ich habe mich entschieden es schließlich doch voll öffentlich for anyone zu machen. Enjoy.
Schon vor der Pest war ich ein Spiele-Fan und habe die Jahre mit diversen Indie- und Coop-Games verbracht. Da meine letzte Games-Liste gut angenommen wurde, ist hier Teil 2 mit älteren Spielen, die mich vor 2020 begeistert haben.
Wieder gilt, es ist ein kleiner Hang zu Indie- und Story-Games. Die absoluten Blockbuster wie Legend of Zelda – Breath Of The Wild, lass ich hier aus.
Der Beginn der Pandemie platzte mein Plan 2020 einige Monate nach Japan zu gehen spektakulär. Stattdessen verbrachte ich die Pandemie einerseits zuhause, andererseits an vielen Orten, die ich danke der Spiele, die ich im Laufe des Jahres konsumiert habe, besuchen konnte. Ich hab schon vorher regelmäßig gespielt, aber über die letzten 18 Monate war es mehr als vorher. Neben einigen bekannte Blockbustern (Age of Empires, GTA, Tomb Raider), aber auch manche wenig bekannten Perlen, die ich hier gerne weiter empfehlen möchte. Dabei spielt es keine Rolle wann die Spiele erschienen sind. 2020 war nur zufällig das Jahr in dem ich sie in die Hand bekam.
2013 kaufte ich mir nach einem Konzert von Amanda Palmer eine Ukulele und spielte ab da täglich. 2019 kanalisierte ich ein überaus frustrierendes Jahr in ein kleines Musik-Album namens Bettlektüre.
Songs hatte ich genug. Über die vergangenen fünf Jahre schrieb ich regelmäßig Neue und auch auf der offenen Bühne Ukeboogie aufzutreten brachte den monatlichen Ansporn etwas Neues zu machen. Dabei entpuppte sich drei Uhr morgens als eine meiner kreativsten Zeiten, wenn ich wach im Bett lag und nicht schlafen konnte.
Den Song Mondtherapie hatte ich bereits 2 Jahre vorher geschrieben. Müde öffnete mir die Tür zu einem Klang, in dem ich mehrere Songs fand, die thematisch zusammen passten. Verloren sein, Suchen, Verlust, Heilen und Finden. Passing Places entstand auf einer Fahrt durch die schottischen Midlands, Schweigen am Mekong in Laos und Seher in folge einer Fahrt durch Irland. Über neun Monate nahm ich die Songs auf, spielte fast alles selbst und lernte zu produzieren. Für manche Songs konnte ich befreundete Musiker dazu holen, für den Gesang buchte ich mich zwei Abende in ein Studio. Am Ende kamen 5 Songs und ein Interlude raus.
Die EP erschien und mit einmal war alles raus und meine Kreativität erschöpft. Ich legte die Ukulele beiseite und jetzt erst ein Jahr später kann ich in die EP hören und genießen, was ich gemacht habe.
Italy, Spain, and other countries are already experiencing shortage of ventilators.
In Germany the crisis is getting worse by the day. Our doctors are already expressing their concerns about the lack of necessary equipment, including vital parameter monitors
Availability of vital parameters such as (peripheral) oxygen saturation (SpO2), heart rate, blood pressure is key in order to judge health status of patients and to keep an overview of all patients in a given ward
Medical doctors who are currently treating hundreds of Covid-19 patients in Northern Italy and Spain (including measures such as a strict triage to provide treatment only to patients with highest changes of improved/positive outcome and converting ORs into ICUs) assess their situation as follows:
Non-ICU setting: measuring vital parameters 3–5 times per day is sufficient in order to determine worsening health situation of patients; currently enough equipment; skeptical to use non-approved technology (e.g. vital parameters via mobile phone), only for stable patients in worst case scenario
ICU setting: continuous monitoring of vital parameters necessary; currently enough monitoring equipment, but shortage of ventilators; skepticism to use non-approved technology (e.g. vital parameters via mobile phone), only for patients with non-invasive ventilation in worst case scenario
Improvised ICU setting: see ICU setting, but: lack of compatibility / connectivity of monitoring equipment with / to central screens, nurses need to keep overview of all patient monitors
Generally: if the situation worsens, the major bottlenecks will be: sufficient numbers of ventilators, of ICU beds, and of trained ICU nurses
Abstract
We evaluated if smartphones can be employed in ICU and non-ICU environments to improve the working conditions of health care workers considerably during a crisis such as COVID-19.
Based on five qualitative interviews with medical personnel from Italy, Spain, and Germany we found that smartphones can be used most effectively for the visualization of vital parameters in temporary improvised ICUs in minor overstressed hospitals due to a prevalent lack of centralized monitoring and relatively low staff stress levels. In this case the data provided for the visualization is provided by professional measurement devices.
However, the interviewees made clear that lack of qualified personnel, equipment such as ventilators, and effective public health policies to stem epidemiological spread are the major threats to their working conditions.
Motivation
This article is the result of a two day remote “#WirVsVirus” Hackathon session organized in Germany March 21–22. The original project was about developing a solution of collecting and displaying vital parameters with an App/Smartphone-based solution as a make-shift replacement to a bedside Patient Monitor.
Having seen the pictures of overrun hospitals and exhausted medical staff communicated in European media, the authors felt it necessary to review the assumptions of the original premise. To do that, interviews were performed to learn about how hospitals are organized, what processes around patient’s vital parameter monitoring are in place and how these processes changed in crisis regions. Hackathons are especially primed for building technical solutions, these can be prototypical or experimental. In our analysis we wanted to provide foundational work for other projects that are pursuing innovative technical solutions in the hope that these projects gain a good understanding of the environment their solutions will have to work in and the challenges that need to be overcome.
Methodology
On March 21 and 22, 2020, five interviews with medical doctors from Northern Italy (3), Germany (1) and Spain (1) were conducted. The interview questions are attached. The interviews were partially conducted in a structured manner, however, not every interviewee answered all questions (least answers about mock-up).
The following gives an overview of the five interviewed medical doctors and their respective situation and experience:
MD from an ICU in Berlin, not yet affected by Covid-19 crisis, knows of a Covid-19 patient at his hospital
Anesthetist from an ICU in Madrid, currently treating numerous Covid-19 patients
Gastroenterologist from a regular ward in Milano (Northern Italy), exclusively treating Covid-19 patients, ca. 300 at a time; hospital has installed a triage to provide treatment only to patients with highest changes of improved/positive outcome
Internist, same hospital as (3)
Anesthetist from ICU in Piemonte (Northern Italy); two operating theatres had been converted into temporary ICUs to meet demand; in total 45 patients (15 per ICU), no turnover of patients for past two weeks
One part of the interview focused on understanding the doctor’s and healthcare worker’s current situation, the equipment and workflows to treat Covid-19 patients. We focused on gaining insights regarding the existing shortage of equipment or other resources, and the expected development and implications of shortages in case of an aggravation of the situation. The goal was to derive root causes for potential harmful situations and related needs to prevent these.
Another part of the interview was a discussion about a fictive monitoring system based on mobile applications for sensing of vital parameters and their visualization, to be used by patients and staff. We evaluated our proposed solution to find it’s drawbacks and misconceptions.
Scenarios
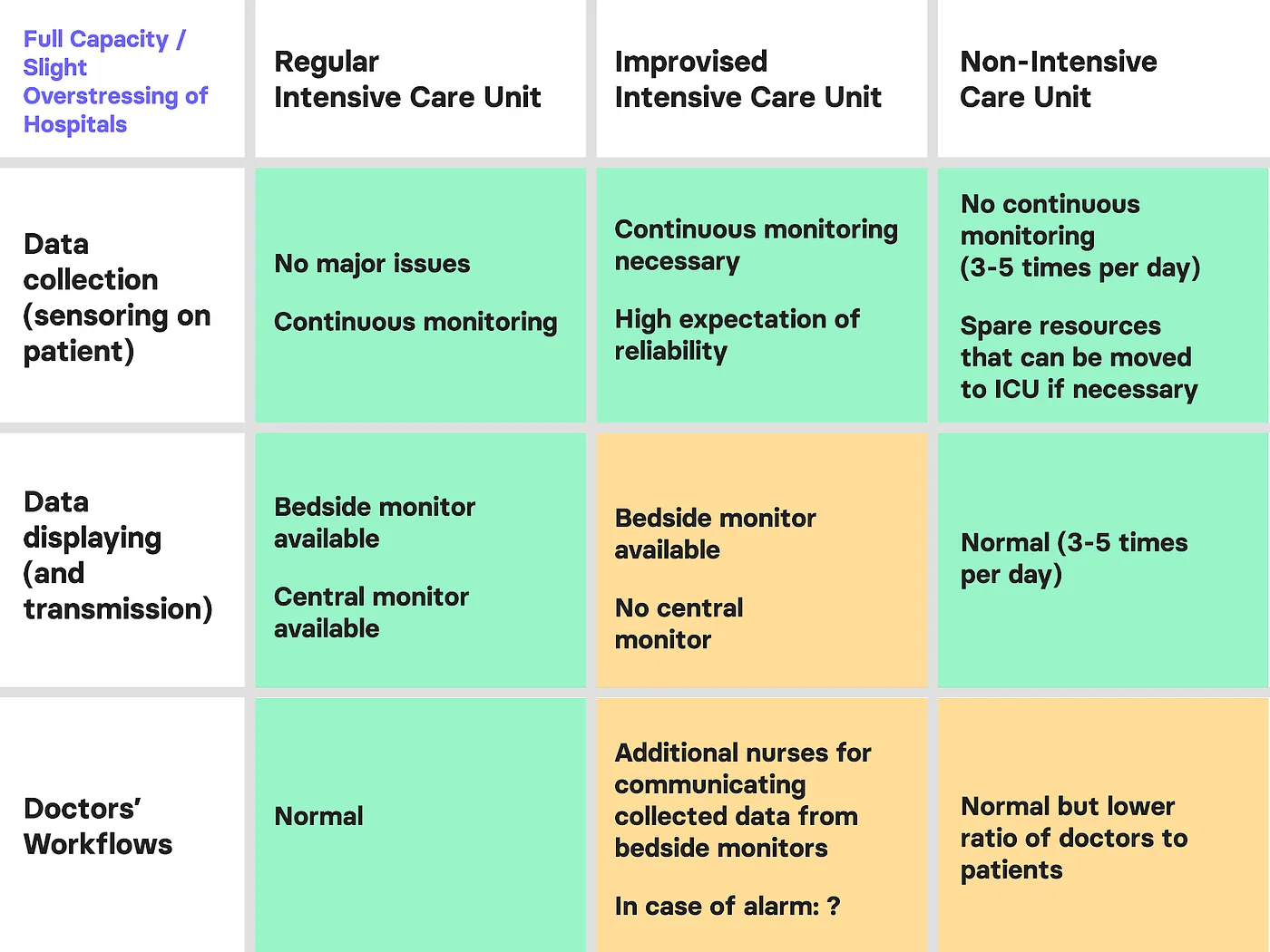
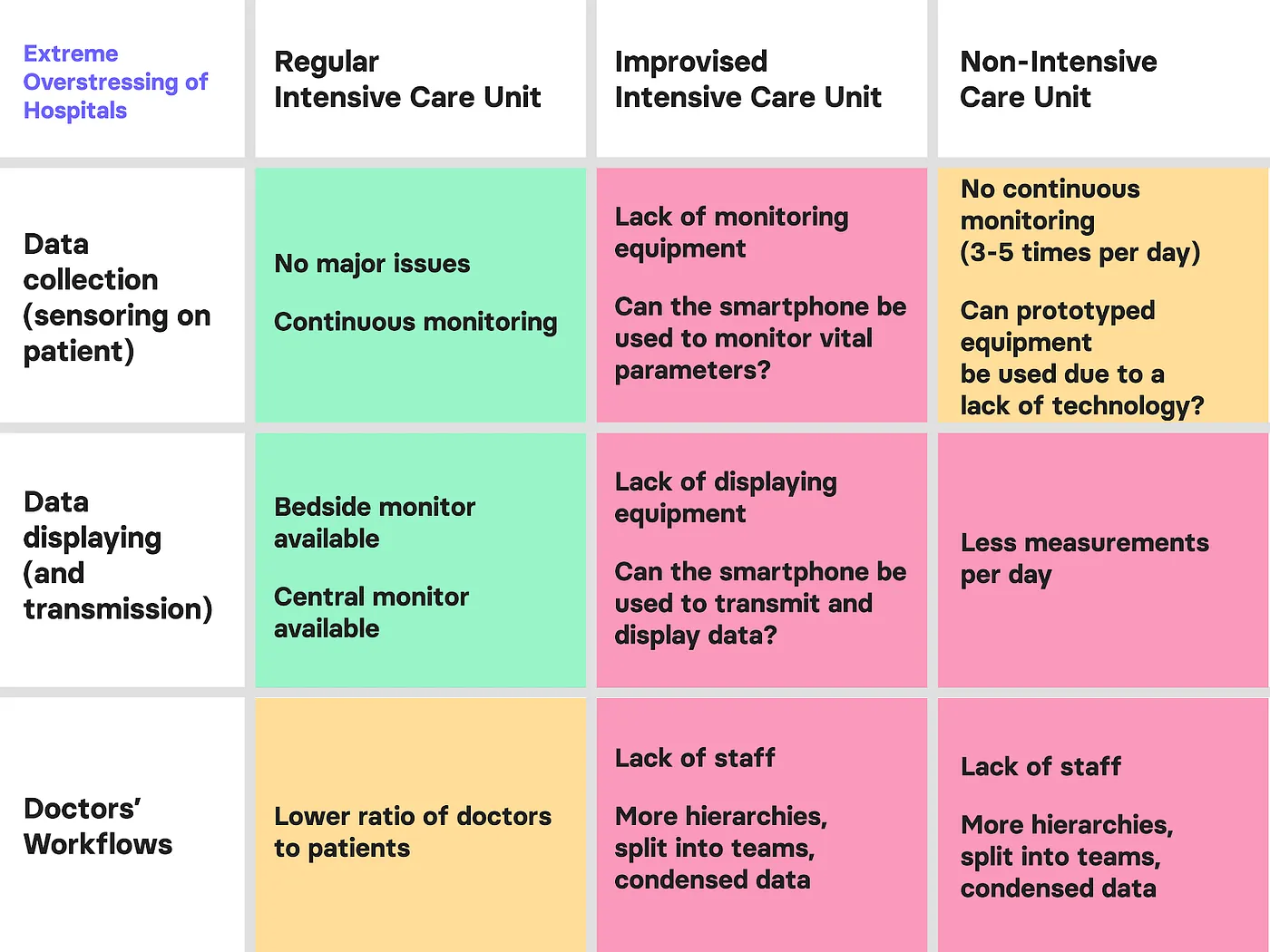
We focused on two main crisis scenarios where ICUs have been temporarily set up in operating theatres and reviewed how personnel workflows are affected by the crisis. The reviewal covers three main points: vital parameter data collection on the patient, data display to the medical staff, and workflow and work conditions of the medical staff.
Data collection can be split into continuous monitoring usually performed by bedside Patient Monitors and intermittent measurements of specific vital signs in regular frequencies usually performed by staff.
Data display is about how the collected data is analysed and made available to medical staff and doctors. It can be available when being at the patient, or if collected and distributed digitally available remotely.
Workflow and working conditions of the staff is about occupancy and stress-level of the onsite staff. Even in regular hospital workload, staff work are highly trained in their daily tasks and yet under high pressure from understaffing. In crisis situations this is exacerbated by factors like mismanagement, technical problems or training of inexperienced people.
In this scenario rooms such as operation theatres are transformed into temporary ICUs because of the higher need. We will use the word extended ICUs and expanded ICUs as synonyms in the following descriptions. These rooms have bedside monitors for the continuous monitoring of patients. However, the data collected by those is not sent to a central unit in most cases.
This is an extension to the Minor overstressing scenario, assuming the amount of people to treat reached a point where triage becomes necessary.
The equipment situation in the regular ICU will not change, however with more doctors and staff having to take care of more patients overall, their time per patient will be much more limited.
This becomes worse in the expanded ICU. Given the makeshift nature, more nurses will be required to handle the load of patients and the additional work by incomplete or missing equipment. Having insufficient Patient Monitors adds work of recording and monitoring patient status. Having more teams also requires more structure within the organization. Students enlisted to support or retirees brought back into service require training and oversight before working effectively.
Thesis
We started this research with the premise of what benefit an app-based monitoring system in case of lacking Patient Monitors could bring.
Our assumption was that in the context of overstressed ICU’s alternative uncertified tools can support health care workers due to a lack of equipment or people power patients may be lost. The proposed mockup would provide Vital Parameters Monitoring to ICU’s not connected to central Patient Monitoring and allow to visualize the live data in both a central room or on the go on health care worker’s phones.
HR and SpO2 estimations are based on creating a photoplethysmogram (PPG) from the rear camera, BP can be estimated using the pulse transit time value calculated from the PPG and phonocardiogram (PCG) recorded using the microphone.
Other ongoing projects suggest that respiratory rate can also be measured using a smartphone’s microphone.
System setup
The software solution discussed in the interviews was a mockup not actually planned for implementation. As such, describing its structure serves to understand the conclusions learned. It’s not a blueprint to implement.
For data collection, patients would install a monitoring app for continuously recording their vital signs and submitting them to a central processing and database server. This backend would provide APIs for accessing the data for display. The server would also include heuristics to send warnings about abnormal or dangerous vital signs.
For display, we discussed the mockups of a mobile client with our interviewees. This would list hospitalized patients for a quick overview of each’s most important live sign reading. A more detailed view analog to the screen health professionals know from the standard Patient Monitors provided additional information and a log of treatments.
Evaluation
If not mentioned otherwise, any information shared in this chapter is based on the interviews as described in “Methodology”.
Status Quo and Needs in Monitoring and Treating Covid-19 Patients
The majority of Covid-19 patients are not in a critical state, some require support for breathing (i.e. non-invasive ventilation such as CPAP). After a potential triage in the emergency rooms of a hospital, they tend to be treated in a regular ward utilized for Covid-19 patients exclusively. The vital parameters of these patients need to be monitored 3–5 times per day, conducted by a nurse in a sequential manner. In case of a worsening health status and need for further interventions beyond medication — such as invasive ventilation — patients are transferred to an ICU. Discharge is linked to a good value of a patient’s peripheral oxygen saturation and needs to be done prematurely if too many patients require treatment.
If ICUs become too full, current practise seems to convert operating rooms into temporary improvised ICUs.
Medical guidelines may differ from current best practise (note: guidelines not researched here; best practices based on interviews, see “Disclaimer”), but here is a summary of the vital parameters that are most decisive when treating Covid-19 patients:
Non-ICU setting
oxygen saturation SpO2 (single most important value)
blood pressure
pulse rate
respiratory rate
ICU setting
oxygen saturation SpO2 (single most important value)
blood pressure
ECG
CO2 in exhaled air (if invasively ventilated)
Here, we can find a significant overlap with the parameters potentially sensed by smartphones (see: Thesis).
In regards to vital parameter monitoring, consisting of data collection (sensoring), data displaying (and transmission), and related work flows, the following situations and needs could be determined:
Scenario #1 — Minor Overstressing of Hospitals:
In this scenario temporary ICUs are used where bedside monitors are not connected to central monitoring units. This creates a need to manually check the vital parameters of each patient in a high frequency by a health worker and report them to other doctors or nurses.
To accomplish this a simple method of writing down all parameters on a paper by hand is used in one of the hospitals, reported by an interviewed health worker. The paper is then stuck to a wall where others can see the parameters to avoid infection by touching paper.
As more doctors are working in the temporary improvised intensive care units, doctors in the non-intensive care units need to monitor more patients as usual.
Scenario #2 — Major Overstressing of Hospitals:
In this scenario temporary ICUs are used where bedside monitors are not connected to central monitoring units. The high number of patients could lead to a lack of bedside monitors and other important data collection devices which amplifies the problem of being able to supervise all patients. Manually checking the vital parameters of each patient in a high frequency by a health worker and report them to other doctors or nurses takes now even more time and effort than in scenario #1.
Furthermore a lack of data collection devices in temporary ICUs could arise more easily. In this scenario the number of deaths will probably be higher because of the uncontrolled patients.
As more doctors are working in temporary intensive care units, doctors in the non-intensive care units need to monitor more patients as usual and have even less time to monitor them regularly. The number of available nurses and other health care workers could be insufficient because of the need for them to treat more severe cases of patients in the temporary improvised intensive care units. The probability of missing out the worsening of a patient’s state in the non-ICUs could increase.
For standard ICU units the ratio of available doctors to patients could also decrease which could lead also there to a lack of control and correct supervising of patients. However, in a slightly less problematic way because of the full equipment of bedside monitors and the central unit monitors which alarm doctors and other health care workers.
Independent from monitoring of vital parameters, the following concerns were raised as most pressing:
Shortage of ICU beds
Shortage of drugs and usage of off-label drugs
Shortage of ventilators. This would mean an even stricter triage.
Shortage of trained personnel (ICU nurses), possible reasons are:
personnel infected because of shortage of PPE equipment
further increase in number of patients
Further problems which arise are around a Loss of control, mainly due to understaffing. If patients cannot be monitored efficiently there is the chance of:
Missing out an alarm which brings the ICU patients into a life-threatening situation.
Delaying the admission of non-ICU patients into intensive care before it’s too late
Compatibility/Interoperability amongst different devices
Prototypical technology (e.g. smartphones) to display the data from side bed monitors in temporary ICUs could create an extra burden to health workers if they need to use them in addition to the commonly used data of the central unit screen.
Smartphones in Hospitals
In a regular ICU monitoring, systems are in place that don’t require additional app-based solutions. In the case of supporting overstressed expanded ICUs app-based solutions can provide benefits where the alternative is to do without.
Smartphones are an ubiquitous amenity for most people, in the daily business of a hospital they are not a regular tool. In the early years of mobile phones, they could even cause interference with medical equipment and where therefore banned. This is not an issue anymore, but phones remain a vector of infection and certain aspects of practicability need to be evaluated. One strength of the smartphone in particular is its versatility through applications utilizing internal or external sensors. Developing an app for reading sensor data from another device or directly from the patient is possible. Getting started on such solutions is not a manageable effort.
In normal circumstances, technology used in medical wards requires a long testing and certification Process. Functionality and user interfaces are standardized and reglemented to facilitate the training of health personnel.
Hospitals handle phones with their employees differently. Some allow phones for notes and look up. Usually phones are not connected to the hospital’s internal network.
Other hospitals are more strict and regard phones by default as contaminated devices not to be brought into wards.
When using a patient’s phone there are three obstacles to overcome. The phone needs to be prepared and the correct software installed for the monitoring. The patient needs to be trained how to use the app correctly. Secondary infrastructure such as power source for the phone or reliable Wifi for data transfer needs to be available to ensure smooth function. Each is critical and if something is not working, it requires health care people to support that is required for more critical tasks.
Reliability and Trustworthiness
In order to have successful use of the system, it needs to be reliable. Staff will be busy doing their regular work and can not afford to second-guess if the shown data or the given alerts are correct.
In order to achieve reliability the system needs testing before deploying it in an emergency. Testing systems beforehand is difficult and hard to do during an emerging crisis. In our setup, critical infrastructure is power supply of the phone and network availability.
If the system relies on patient support — for example by holding the app in a special way — usage mistakes need to be avoided. What if the patient is not cooperative or has no phone available.
It’s important to identify and review assumptions where you have to assume goodwill or ideal circumstances. People will be stressed and things may fail, and failing things will cause more stress.
Health care workers are not against adopting new technologies, if it supports them in their job and does not get in the way.
They are used to professional licensed medical equipment and they will prefer it as long as the situation and capacity allows. Should make-shift measures get introduced, the lack of space and level of exhaustion will have everyone already stressed out. Staff may prefer not use such a solution if it causes more distraction and confusion than it helps to save lives.
Feedback on Mockups
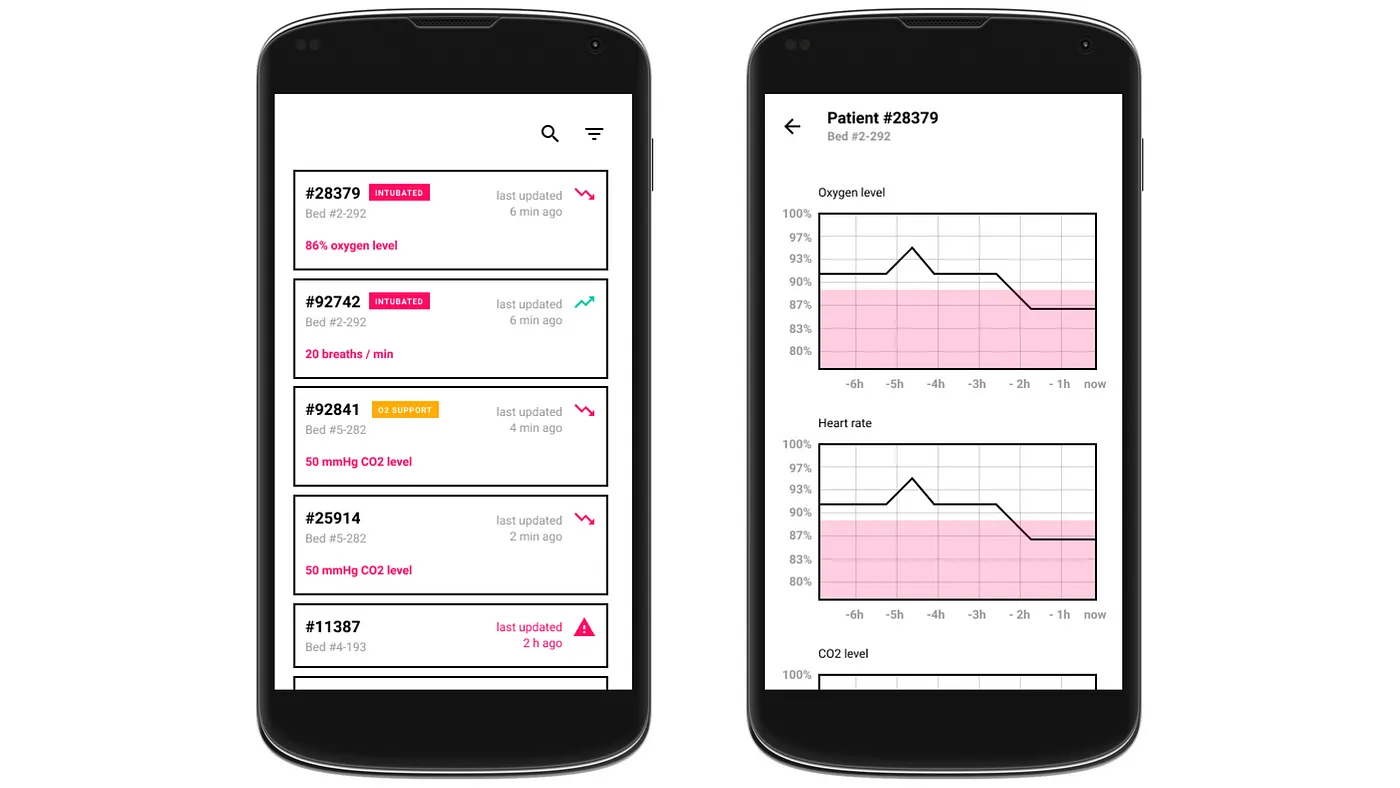
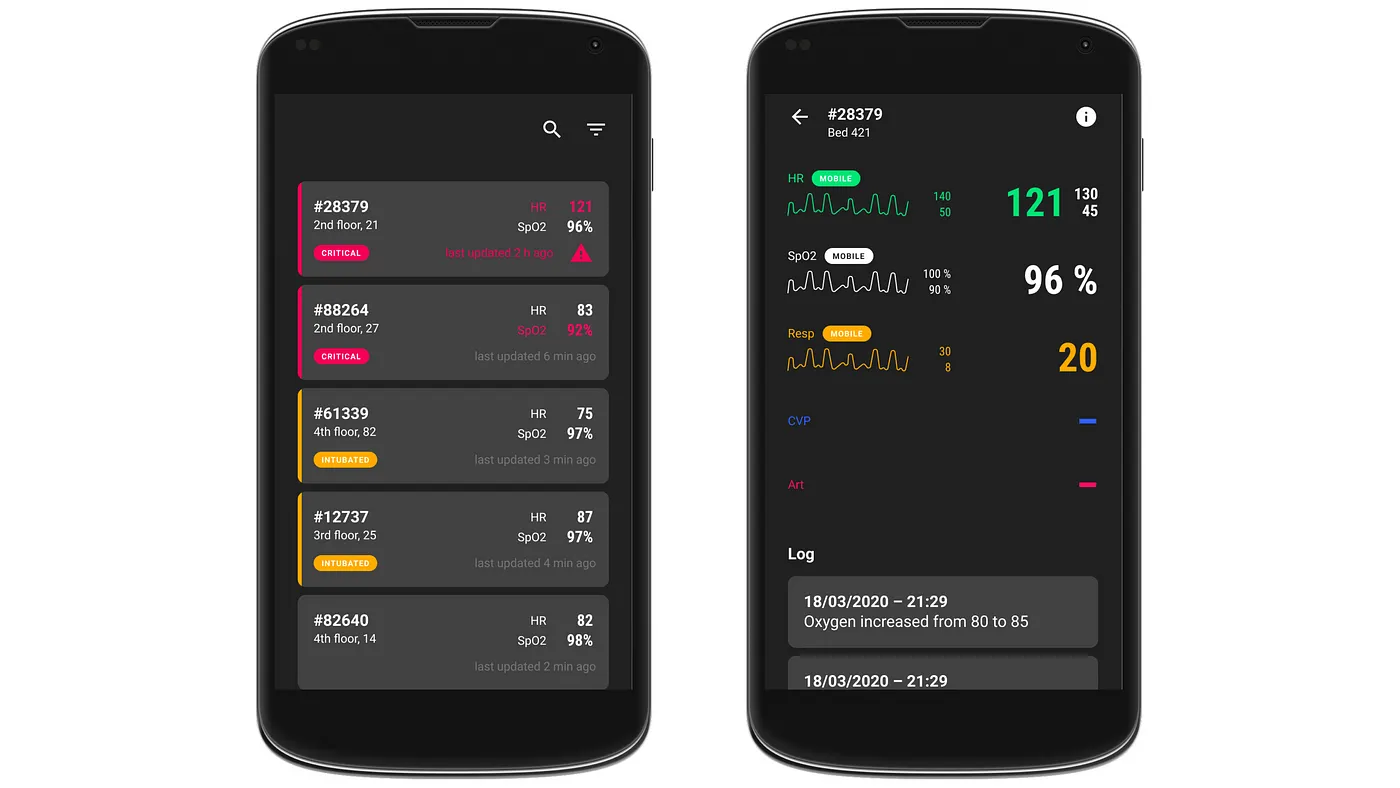
In order to test our initial assumptions, we created clickable prototypes of an app to gather more specific feedback from the doctors and health care workers in the interviews.
In the first version, the feedback was generally positive. The interviewed doctors showed a positive reaction of using their smartphones for being able to monitor patients on the go or when convenient. However it became clear that doctors are very accustomed to the view of traditional monitoring devices in hospitals. Hence the visual design had to lean more against them. Therefore, we moved to a UI in dark mode for the second iteration and used a more conservative visualization of graphs and colour coding.
First mockupSecond mockup
We also learned that the data that’s relevant for doctors varies significantly depending on the state of the patient. For patients who can still breathe by themselves or with oxygen support, data like the oxygen saturation and blood pressure are more relevant. With intubated patients on the other hand, it is more important to see the settings on the machines.
As for the sorting of the list in the patients’ overview, we learned that there are two types of alarms: red and yellow. A red alarm is the most critical one and occurs for example if a patient stops breathing or his / her heart stops beating. These patients must thus also be displayed at the top of the list as their state is the most critical.
Alternative proposals
While evaluating our proposed solution, alternative approaches were discussed. They are not detailed, but describe some requirements and solutions that could warrant further attention.
Requirements
Something all solutions have in common is, that they need practical testing before the actual deployment in a disaster situation. Even during a pandemic like Covid-19, not all areas in the work are affected the same and solutions can be tried in places where outbreaks are not imminent yet.
The reliability and scalability of the process or the technology needs more testing. This applies both to the infrastructure, hardware and software, as well as training, deployment and monitoring.
The solution should have the least amount of assumptions. Integration and use needs to be testable and be monitored to evaluate its effectiveness and discover potential for improvement.
Engineers tend to see a problem and want to fix it with technology — sometimes solutions with simple proven technology are the best for the job. Reflecting if Pen and Paper work better than an App is necessary to put the outcome over the solution.
In the end, it has to make life easier for people. If it is no help, it shouldn’t be used in disaster.
Compensating Shortage of Ventilators
A single ventilator may be quickly modified to ventilate four simulated adults for a limited time.
A simple solution would be to use the webcam of a smartphone (maybe the patient’s smartphone) to record the screen of the bedside monitor. Every few seconds the latest image of the screen of each patient will be displayed on the smartphone of the health care workers after selecting the specific patient. A special holder would be needed to place the smartphone camera pointing to the right direction and to record the full monitor. The battery on the phone at the bedside monitor could be charged constantly in place.
The disadvantage of this solution is that a regular check of health care workers on their phones is still needed, since they would not get notified by alarms from the bedside machine.
Specialized standardized Emergency equipment
Ideally, a specialised low-resource Emergency kit for Patient Monitoring could be developed with the potential dual use for disaster relief efforts. These kits would either be cheap and fast to produce or small, durable and cheap to stock. Open access to data interfaces would allow external applications and services to hook in to provide expanded functionality at scale.
Handling would be standardized and staff would receive limited bi-yearly training to refresh usage. This would be the go-to solution for quick scaling of Vital Parameter monitoring.
The author’s did not research availability and quality of existing emergency kits. No such usage was documented in the interviews.
Conclusion
In times of disasters or crisis such as the COVID-19 pandemia, it becomes even more crucial to determine the problems where solutions would have the highest positive impact on the overall situation. It can be key, more than ever, to involve people from the “front line” early on in the problem finding and ideation process and to take a human-centered approach when designing solutions.
Although the reaction of the health workers was positive to the proposal of using prototypical technology such as a smartphone for vital data display in temporary ICUs, it would need a deeper analysis and testing of a prototype in the real world.
Doctors were very hesitant when considering the option of using smart phones to actually sense vital parameters. Here, it needs to be assessed even more carefully if this path should be taken, if this becomes necessary, or if there are other possibilities to monitor and treat patients with approved equipment only while scaling up capacity.
Have you been involved with Covid-19 patients so far?
Are you preparing for a run of Covid-19 patients?
What are your top 3 pressing concerns right now?
Patient Journey
Can you talk me through the process when a Covid-19 patient comes into your ward?
Talk me through how you would monitor a Covid-19 patient throughout the time in your ward?
What changes do you expect in these processes if you would need to deal with hundreds of patients at a time?
If you were to deal with hundreds of patients simultaneously, where and when would it be most likely that you lose control? What part of the patient journey and for what reason?
What about temporary rooms which are used now because of missing beds and space problems? How are people monitored there?
If we could organize one thing for you, to ease your load on the ward, what would it be?
Vital Parameters
If you could get only one vital parameter of each Covid-19 patient, which one would you take?
What other two pieces of information are most crucial?
Based on what vital parameters do you take most of your decisions and how do they need to be presented?
General
Are you currently using equipment that is not CE marked? Could you imagine to use such equipment during a crisis?
For what kind of patients would you use monitoring of patients via mobile phones?
Mock-up related questions
Please describe what you see
How often do you usually check a patient’s vital signs?
Is the provided data in the home screen enough for health workers to understand the criticality of a patient’s conditions?
What is the important static data a doctor needs to have access to on the go?
What dynamic data is important? Heart rate, oxygen levels, CO2?
If you need to go deeper than the information provided on the home screen, what information would be helpful to you?
How realistic is it for you to use an app in such conditions?
What could potentially stop you from using it?
Is there anything else you’re missing from the app?
When I started my first job I had a colleague who only worked 4 days a week and I knew, this is something I want to try too. So when I interviewed in my current company, a 36-hour workweek was one of the first conditions we agreed on. Working in Germany, this used to be a regular week length, but for over a decade 40 hours have become the norm. It was a agreed. As a developer, this never posed an issue. As I switched into Product and Project Management, I resisted the expectation to go full-time. What this decision meant for my work, I’d like to share with you.
Reduced time as a developer
Doing a 36 workweek as a developer was easy, because you can work quite independently. As long as everyone could retrace where I am, it was no topic. So I created my ‘availability calendar’ and put any home office or off hours at least a week in advance in there.
Getting asked if I want to extend my working hours became an annual ritual with my bosses with everyone knowing I wouldn’t do it. Everyone was happy with the arrangement, so why change what’s working.
When I became a Senior Developer I was cautioned — moving into a position of higher responsibility would also mean having to go full-time. We would talk about it when it becomes necessary.
It never happened. I became a Product manager on my 36 hour work schedule. Granted, I’m new to Product management with only 2 years experience at this point, and it was a gradual switch from engineering – no one questioned the existing setup. Eventually, before anyone could ask again, I’d shown the job can be done with my established time management.
Mini vacation once a week
I usually take my four free hours as a block. I’s easier to switch off for me and also for the company to track my work hours. The timing switched over the years though, it was Wednesday, then Thursday, now Friday. It depends on the sprint rituals and other recurring meetings I have to consider.
And of course it also depends on my hobbies. Or when I want to get a good sleep in. Or when I really need to do some household activities, or administrative duties. Being able to manage my private life’s necessities in the 4 hour I take ‘off’ from work, means I have much less disruptions in my work schedule than the average colleague.
The effect of having a mini vacation should also not be forgotten or understated for that matter. I realize after working in this setup for years now, I feel much more refreshed and can perform better over the duration of the whole week compared to when I put in overtime and end up working the 40-hours. It makes a noticeable difference to me, and my company benefits from it too. Burnouts and keeping good mental health in creative jobs are recurring topic nowadays, and having shorter weeks can really help with this too. Everyone wins, yay!
What about my manager job?
It’s important for me that my personal values are reflected in my workplace and my position. Independence is one of those for my own work and also my colleagues working proficient and autonomous.
As a manager I see myself as the one who enables other people to build awesome things. My task is removing any road blocks my colleagues may have. Being unavailable for a few hours every week, requires them to foster this independence. My colleagues can rely that I’m available on the given times. Outside of work, I leave my phone and Slack off. If something is blocking them, they know when they can get their answers, or they are creative to work around it and find their own solution that they check with me later on.
This off-time actually helps to find these blockers and eliminate them, thereby growing independence and autonomy in the team.
Another aspect is Parkinson’s law. If you have a work and a given time slot, the work will expand into the time available. Working slightly less hours, forces me to do the job in shorter time and thereby focus on the priorities. And don’t even get me started on the negative effects of working beyond 40 hours.
Crunch time
“This all sounds nice and well, but what about deadlines and launch dates? The usual craziness that can be product?” I hear you asking.
Let me tell you about the flexibility that comes with a 36 hour arrangement. It’s actually like having a load balancer when a big release is coming up, of course I pull my part and go 40 hours. I log these as overtime that I take off when times are calmer again. Again, this is about transparency, expectation and supporting the team the right amount at the right time.
From a company point of view, this load balancing has another effect: they have me as a quality employee slightly cheaper, since they pay less hours in total.
My current setup is comfortable and privileged. I’m aware that with rising responsibilities it may not hold up forever. At a certain management level, you are expected to be always on and as you care for your projects, you may want to be. Something is always in need of support and you do want to provide that. My goal is to keep on working on strategies to keep my arrangement for as long as possible.
Is this a privilege? Hell yes!
In my working live I inspired at least three colleagues to reduce and be more flexible about their working hours. I have two more Product management colleagues who work only four days.
When I’m talking with Engineering students and mention this, I can see their eyes lighten up. They never considered this option for themselves before. I know for most people in many industries it is not so easy to negotiate their hours. I hope by being transparent about it, I can help make it become a new normal.
So consider this as a topic for your next negotiation. It’s not always about the money, your time is valuable too!
In our company, we experimented the last year with various setups of Cross-functional teams. These teams consist of members from different departments for a limited time to implement a specific goal. They do not have to be IT-focused, but coming from an IT background my experience is from being in and leading IT- and Product-focused teams.
If you are reading this setup guide, chances are high that you want to set up a new Cross-functional team. Awesome! This guide should give you a hand in where to start and what the main questions you and your team should discuss are.
Goal
What is the goal of the team? Most likely, it’s an implementation requiring close communication and high-level understanding of a specific domain.
When organizing the team, be clear what is expected of the team. The scope needs to be known by all in the team and by all external stakeholders.
In the first two weeks, bring it up often and repeat, so everyone can align on this. Repeat one time too often, rather than not enough.
Depending on how clear the goal is, it can be helpful to define a mission statement everyone can agree on. In discussions about the team’s direction, this can serve as a compass.
What is the goal of the team?
What are the must-haves and what are nice-to-have’s?
Which deadlines exist?
When does the team regularly end and how?
Under which circumstances can the team end without reaching its goal?
Can the goal be summarized with a generic mission statement?
And lastly, the fun part: what’s the team name going to be?
Side topics
When defining the scope, you will find topics that are core to the implementation and topics that are on the side — still on topic, but not required in the MVP. Identify those and put them on the side. It helps being aware of these topics and in discussions about scope, it is good to be able to point to this list to not get distracted. Over the course of the team’s existence, these topics may be revisited, as they gain more importance or as they become valuable as filler work in case the core functionality requires waiting periods.
Where to draw the line between core goals and side topics?
What freedom has the team in defining or redefining the scope?
Organization
Past cross-functional teams in my company have all tried to follow an agile approach, but it was up to each team to define what they meant by this. Some teams chose a structure like Scrum, others went for Kanban. If the team’s goal is well-defined with a deadline, even an approach similar to Waterfall is possible and can serve the purpose. Of course, hybrids can also be discussed. This can be interesting when it comes to communication and rituals. More on this later.
Does the team want to work towards one big goal?
What milestones can be identified?
Can the work be broken into iterative steps?
What steps depend upon each other?
Reporting
The team was set up for reaching a goal and somebody is interested in the progress towards this goal. There may be multiple stakeholders that need to be kept in-the-loop:
departments and their heads requesting the feature
management or execs
maybe a department is affected in case of success which is otherwise not involved over the term of the cross-functional team
Identify who needs to get what kind of updates and how frequently they should be updated. Schedule regular updates, so they don’t have to ask and can trust to get informed as the team moves ahead. This can be meetings, but — if agreed — updates by mail or other means may be fine as well.
If your IT developers have Sprint Reviews, ask to use this platform to inform a wide range of people about your updates.
Who requires knowledge of the progress of the team? Which departments, heads, management members?
How often should they be informed?
In what format do they want the updates?
Can the work presented in the IT Sprint-Review?
Roles
Whether the team is set up with one Tech Lead coordinating its strategy and implementation or with a flat hierarchy may be outside of the scope of the team. If this was not defined, it is up to the team to agree if they want to have a layered or flat hierarchy. In smaller teams, flat structures proved working fine.
One recommendation for teams with flat hierarchies is to define roles within the team. Roles may emerge automatically from the tasks, i.e. Developer and Project Manager. Even within a group of developers you will find small-scale responsibilities that are worth talking about in the team.
Either way the hierarchy is set up, the team should have one person who is the first contact for outside stakeholders. She should receive and distribute messages from and to the team. This does not mean, other team members are asked to not directly communicate to outside stakeholders, just that the team contact should be aware of the communication. Summaries are best practice.
The team can decide to assign one member to attend the stand-ups of the IT-Dev teams to be aware of their topics and identify when topics of both teams intersect. We are going to talk about the importance of retrospects below, organizing them could be another task for one team member. Another role could be somebody to remind updating tasks and tickets.
During the existence of the team it may happen that somebody goes on vacation. Remember to prepare handovers and assign replacement(s) for the roles in vacation.
What is the hierarchical structure?
Is there one Tech Lead or a flat structure?
Who is the first contact in the team?
Who organizes meetings like retrospectives?
Is somebody interested in attending the Sprint Standup?
Who is responsible for taking care the team keeps updating their todos and status?
Does anyone have leave planned during the existence of the team?
Documentation
Setup a Confluence/wiki page describing who is in the team, what the goal is, and how you organize yourselves. Any decision the team makes about its structure can be noted there.
After the team is done, this page is also helpful for documenting how the team was set up and about the learnings of the speedboat.
Who is responsible for taking care about the care setting up and updating the team’s Confluence page?
What topic should be documented?
Meetings
Be aware that different team members work on different schedules. People with Manager’s Schedule have their day split into many blocks due to meetings and context switches. People in Maker’s Schedule tend to have an empty calendar with long blocks working on one subject without distractions.
The team should discuss which regular meetings it deems useful.
Perform regular retrospectives within the team, to have a safe place where anyone can bring up a topic.
If your team lacks people experienced with facilitating this kinds of meetings, think about calling in outside help to get you started.
What daily or weekly update meetings does the team want?
How regular should retrospectives be scheduled?
Who wants to facilitate the retrospectives?
What meetings of the IT-Dev team does the team want to attend?
Codebase ownership
This topic very much depends on how the IT-Dev team and the cross-functional team are aligned on their goals.
The recommendation is to separate the codebase the team has to touch from the codebase the ongoing IT-Devs will work on. For the duration of the project your team may get temporary ownership of the codebase. The Dev-team may still do changes, but has to check-in with the team to ensure their changes don’t interfere.
Circumstances may demand both teams to work on the same codebase, which should be reflected in closer communication between the two teams. This includes talks about intentions (what does each team plan to do next) as well as review (reviewing each other’s contributions). Think about attending each other team’s standups, sprint plannings and inviting members of both teams to pull requests.
Which applications are included in the project scope?
Can the cross-functional team take ownership of these projects for the duration of the project?
How should the two teams announce, review and publish their work when working on the same codebase?
Communication
In the last few sections many aspects of communication were already addressed. The experience with previous teams was that this is the topic that can cause the most friction within or outside the team and motivated this document in the first place.
Difficulties within the team can be around ticket status or their lack of updates. Depending on the structure, pair programming may be encouraged to share knowledge and help problem-solving. Mix the pairs frequently, if two strong programmers pair often, they may progress rapidly ahead of others, making it hard for the rest of the team to catch up.
Define with your team how to handle people working remotely.
Make it clear, who to report to in case of sick leave. At the very least HR needs to be informed, writing to other team members is a courtesy.
Summaries (for example in confluence) of what happened when team members were out due to vacation or sickness are generally appreciated.
What are the expectations about announcements and visibility of Home office?
Who takes care of writing a summary when members return from leave?
Ending the team
The nice things about temporary cross-functional is their limited length. You can specifically plan the teams deadlines and use the last week for cleanup, handovers and documentation.
Have one final retrospect about the term of the team — and make sure you have a nice party! Document the topics the team worked on and the lessons learned in your team’s Confluence page. Talk with the IT-Dev-team, as they are likely interested in a summary of the team’s experience.
Similar to the beginning, it is important to align with the stakeholders again. Have meetings with the relevant departments to present how the team’s goals were met.
The scope of these presentations depends on your audience. Most departments are fine with a higher level explanation, while the IT-team will appreciate technical details.
Evaluate if the cross-functional team was worth it — afterall it is an expensive approach and answering this questions helps to make the decision, to setup a new team, easier next time.
Was everything done as expected?
What might be missing?
How do you deal with remaining side-topics?
What changes had to be decided on?
What departments should be informed about the results of the cross-functional team?
What are the lessons learned (technical, data or process-wise, organizational)?
How was the mood in the team?
How did the other team feel with you gone?
Was the team worth the effort?
Final remarks
Take everything I described here as a recommendation. The team you setup will be unique and is free to make their own choices. Feel free to come up with ideas that are not documented here. Cross-functional teams are a great way of experimentation!